
Cel: usunąć ze zbioru tekstów “prawie-duplikaty” - z każdej grupy tekstów o podobnej treści pozostawić jeden.
Współczynnik (indeks) Jaccarda
…to po prostu stosunek liczności iloczynu dwóch zbiorów do ich sumy:
#(A ∩ B) / #(A ∪ B)
Odpowiada na pytanie: “Jaki odsetek wszyskich elementów jest wspólny dla obu zbiorów?”, a wziął się z zainteresowania p. Jaccarda tym, jaki odsetek gatunków rosnących na jednej łące alpejskiej rośnie także na drugiej.
Współczynnik Jaccarda pozwala sprawdzić podobieństwo dwóch zbiorów. Zbiory o identycznych elementach mają współczynnik Jaccarda równy 1, zbiory bez żadnych wspólnych elementów - 0.
Prosta implementacja w Pythonie
import re
def to_words(sentence):
return [w.lower() for w in re.findall('\w+', sentence)]
def jaccard_similarity(txt1, txt2):
"""
# sanity checks
>>> jaccard_similarity("","")
1.0
>>> jaccard_similarity("test","")
0.0
# 1 of 2 words in common
>>> jaccard_similarity("bar foo","bar")
0.5
# order doesn't matter
>>> jaccard_similarity("bar","bar foo")
0.5
# case doesn't matter
>>> jaccard_similarity("Bar","baR foo")
0.5
# non-word characters are ignored
>>> jaccard_similarity("bar,","bar: -foo-")
0.5
# numbers are OK
>>> jaccard_similarity("1","2 1")
0.5
# repeats don't matter
>>> jaccard_similarity("bar bar","bar")
1.0
"""
ww1 = set(to_words(txt1))
ww2 = set(to_words(txt2))
total = len(ww1.union(ww2))
if total == 0:
return 1.0
common = len(ww1.intersection(ww2))
return 1.*common/total
if __name__ == '__main__':
w1 = 'To jest pierwsze zdanie.'
w2 = 'To nie jest pierwsze zdanie, tylko drugie.'
print(jaccard_similarity(w1, w2))
print(jaccard_similarity(w2, w2))
Wynik:
$ python jaccard.py
0.5714285714285714
1.0
Doctesty
Przy okazji dopisałem doctesty, tj. krótkie testy wyglądające jak sesja
interaktywna, przeznaczone do dokumentowania działania funkcji/modułów.
Wystarczy w komentarzu do funkcji wpisać polecenia interpretera i oczekiwane
wyniki. Testy można uruchomić “z modułu”: python -m doctest [-v] <plik.py>.
Ciekawostka: Umieszczanie testów tuż obok kodu który sprawdzają może
wydawać się dziwne programistom przyzwyczajonym do osobnych plików/klas
testowych. Doctesty nie zastępują zaawansowanych, “normalnych” testów,
sprawdzają się za to świetnie przy… dokumentowaniu działania funkcji.
Język D ma w standardzie mechanizm zbliżony do doctestów - blok unittest
pozwala pisać testy w tym samym pliku, co “normalny” kod. Dość typowe jest
umieszczanie testów tuż poniżej funkcji, którą sprawdzają; można
się przyzwyczaić. Więcej na wiki D-lang.
Eliminowanie duplikatów
Prosty algorytm usuwający zduplikowane teksty:
from jaccard import jaccard_similarity
def detect_duplicates(texts, threshold):
to_rm = set()
for i in range(0, len(texts)-1):
for j in range(i+1, len(texts)):
txt1 = texts[i]
txt2 = texts[j]
sim = jaccard_similarity(txt1, txt2)
print('"{}" / "{}") => {:.2f}'.format(txt1, txt2, sim))
if sim > threshold:
to_rm.add(i)
return to_rm
def remove_duplicates(texts, duplicate_indexes):
unique = []
for i, val in enumerate(texts):
if i in duplicate_indexes:
continue
unique.append(val)
return unique
sample_texts = [
'a b c d e f g h i j',
'a b c d e f g h i 1',
'a b c d e f g h 1 2',
'0 1 2 3 4 5 6 7 8 9',
'0 1 2 3 4 5 6 7 8 x',
'x y z',
]
to_rm = detect_duplicates(sample_texts, 0.8)
unique = remove_duplicates(sample_texts, to_rm)
print('unique:')
print(unique)
Wynik:
$ python rm_duplicates.py
"a b c d e f g h i j" / "a b c d e f g h i 1") => 0.82
"a b c d e f g h i j" / "a b c d e f g h 1 2") => 0.67
"a b c d e f g h i j" / "0 1 2 3 4 5 6 7 8 9") => 0.00
"a b c d e f g h i j" / "0 1 2 3 4 5 6 7 8 x") => 0.00
"a b c d e f g h i j" / "x y z") => 0.00
"a b c d e f g h i 1" / "a b c d e f g h 1 2") => 0.82
"a b c d e f g h i 1" / "0 1 2 3 4 5 6 7 8 9") => 0.05
"a b c d e f g h i 1" / "0 1 2 3 4 5 6 7 8 x") => 0.05
"a b c d e f g h i 1" / "x y z") => 0.00
"a b c d e f g h 1 2" / "0 1 2 3 4 5 6 7 8 9") => 0.11
"a b c d e f g h 1 2" / "0 1 2 3 4 5 6 7 8 x") => 0.11
"a b c d e f g h 1 2" / "x y z") => 0.00
"0 1 2 3 4 5 6 7 8 9" / "0 1 2 3 4 5 6 7 8 x") => 0.82
"0 1 2 3 4 5 6 7 8 9" / "x y z") => 0.00
"0 1 2 3 4 5 6 7 8 x" / "x y z") => 0.08
unique:
['a b c d e f g h 1 2', '0 1 2 3 4 5 6 7 8 x', 'x y z']
Oczywiście to marny algorytm - rezultat zależy od kolejności wpisów, bo podobne teksty będą łączyły się w łańcuchy. Np. w ciągu “ala ma kota”, “jacek ma kota”, “jacek ma psa”, “jacek widział psa” każde kolejne zdanie jest podobne do poprzedniego, ale różnica rośnie z każdym przekształceniem. To może prowadzić do zbyt ochoczego kasowania:
sample_texts=[
'a b c d e f g h i j k l m n o p',
'b c d e f g h i j k l m n o p',
'c d e f g h i j k l m n o p',
'd e f g h i j k l m n o p',
'e f g h i j k l m n o p',
'f g h i j k l m n o p',
'g h i j k l m n o p',
'h i j k l m n o p',
'i j k l m n o p',
'j k l m n o p',
'k l m n o p',
'l m n o p',
'm n o p',
'n o p',
'o p',
'p',
]
# unique: ['l m n o p', 'm n o p', 'n o p', 'o p', 'p']
#
# Tak, "klmnop" jest wg naiwnego algorytmu bardzo podobne do "abcdefghijklmnop".
Po przetasowaniu danych wejściowych dostajemy inne wyniki, bo między dwa podobne teksty może trafić trzeci, mniej podobny (“ala ma kota”, “jacek widzi psa”, “jacek ma kota”), co przerwie łańcuch:
import random
random.shuffle(sample_texts)
# unique:
# ['p', 'm n o p', 'n o p', 'o p', 'h i j k l m n o p',
# 'e f g h i j k l m n o p', 'k l m n o p']
#
# ['n o p', 'o p', 'm n o p', 'p', 'i j k l m n o p',
# 'f g h i j k l m n o p', 'l m n o p',
# 'b c d e f g h i j k l m n o p']
#
# itd.
W wypadku długich, rzeczywistych tekstów takie przypadkowe podobieństwo nie występuje tak często jak w sztucznych danych.
Przykład z życia wzięty
Używając powyższej metody oceniłem wzajemne podobieństwo prawie 500 tekstów, z których część mogła być “prawie-zduplikowana”.
Ocena podobieństwa
Jak wygląda wzajemne podobieństwo tekstów w moim zbiorze? Pandasowy DataFrame
ma funkcję hist() do rysowania histogramów:
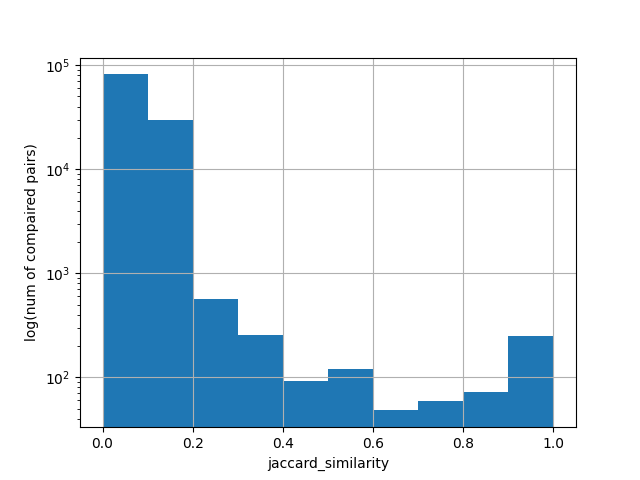
Które teksty są podobne do których? Seaborn pozwala łatwo wizualizować heatmapy:

Filtrowanie
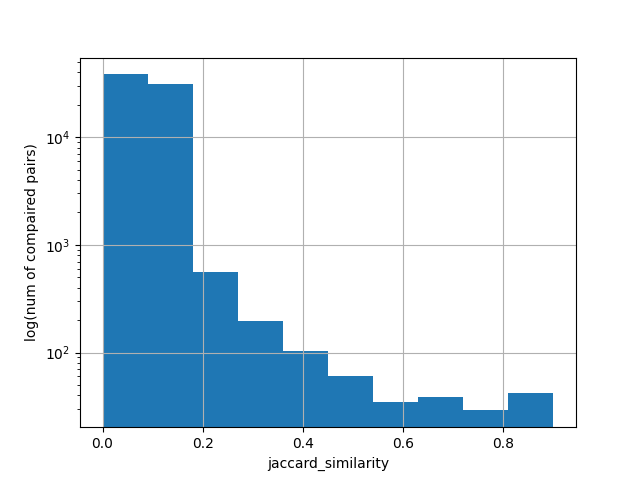
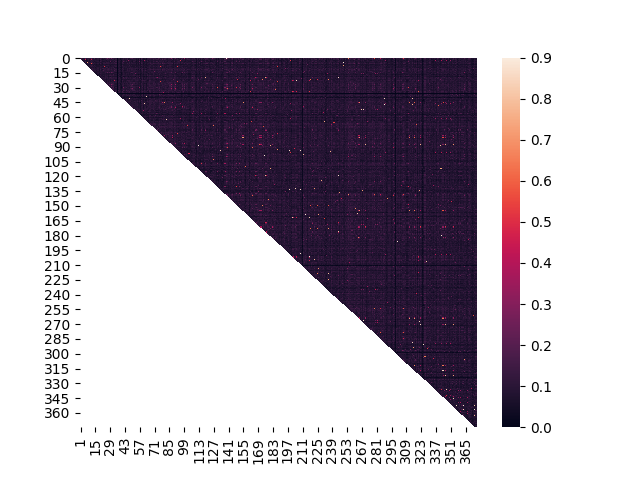
Po usunięciu duplikatów (indeks Jaccarda > 0.9) z 475 zostało mi 376 tekstów.
Histogram:
Heatmapa:
Rozmaitości
- Ten algorytm jest banalny, ale działa!
- Komplementarna metryka (“odległość Jaccarda”) opisuje jak bardzo niepodobne są zbiory.
- Współczynnik Jaccarda opiera się o zbiory (bez powtórzeń), przez co “gubi” informację o częstotliwości występowania słów. Gdyby było potrzebne bardziej precyzyjne filtrowanie, niezłą alternatywą mogłaby być wektoryzacja w oparciu o Bag Of Words i oparte o nią klastrowanie.
- Pythonowe operacje na zbiorach są szybkie, wyciąganie słów z tekstu za pomocą
re.findalljest wolne. Implementacja z przykładu jest niewydajna, bo niepotrzebnie przetwarza tekst na zbiór słów przy każdym porównaniu; łatwo to poprawić.
Linki
- Współczynnik Jaccarda w Wikipedii: https://en.wikipedia.org/wiki/Jaccard_index
- Publikacja Paula Jaccarda (o różnorodności gatunkowej na łąkach alpejskich): https://doi.org/10.1111/j.1469-8137.1912.tb05611.x
- Doctesty: https://docs.python.org/3/library/doctest.html